CHEESE Prototypes
CHEESE web app is only the tip of the iceberg of upcoming features and prototypes. Here we present some of the prototypes that are currently in development. Prototypes are trying to answer some of the frequently asked questions such as whether is possible to search by a whole dataset of molecules, if we can construct more advanced search queries and if there are another metrics that can be learned not only on pair of smiles, but on protein sequences or protein-ligand pairs.1
Are you interested in our prototypes? Contact us at mama@themama.ai. We are eager to discuss your ideas and needs. Access to some of the protypes is available upon request too! We are actively cooperating with chemists to try new suggestions and desired feature requests.
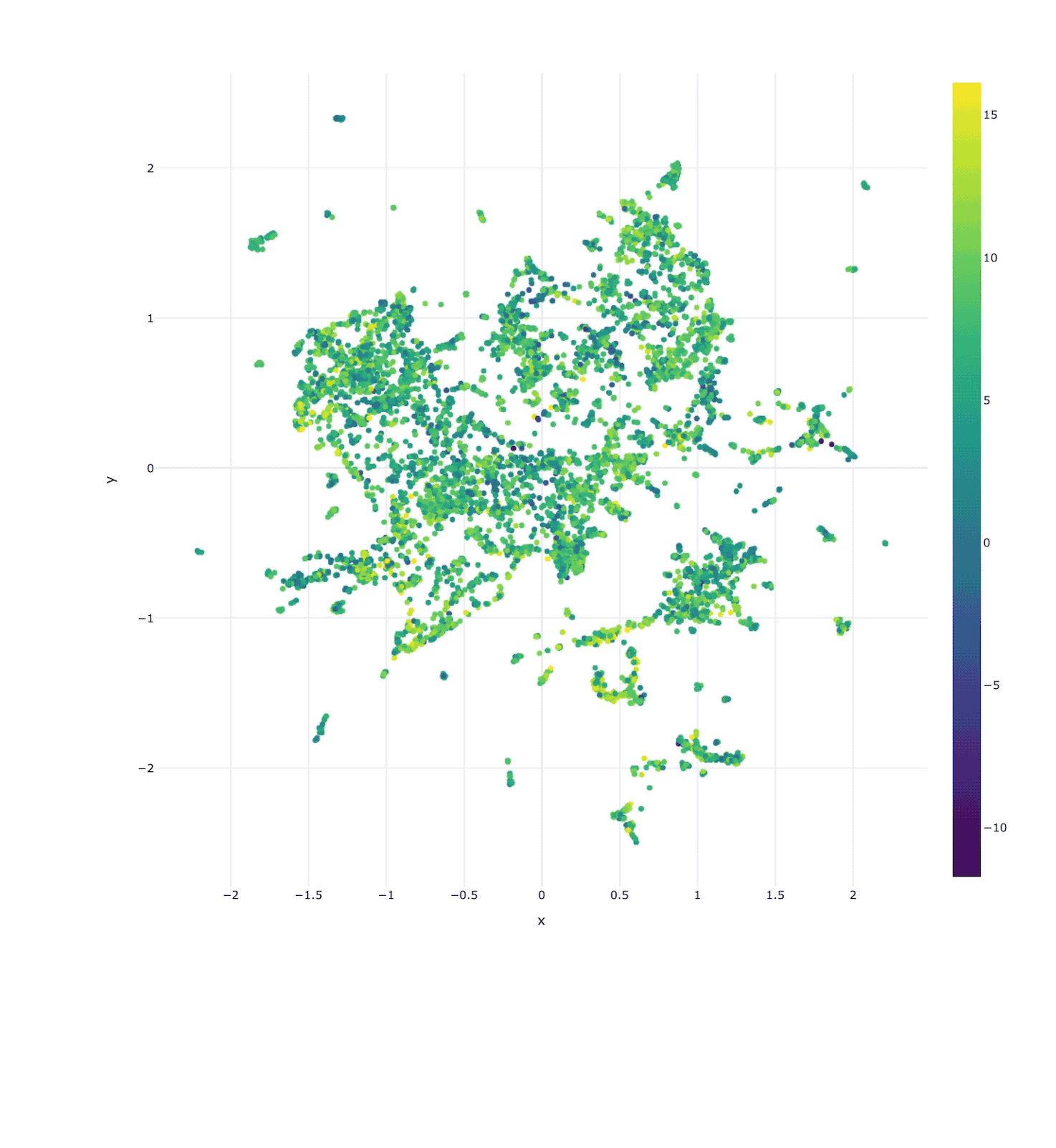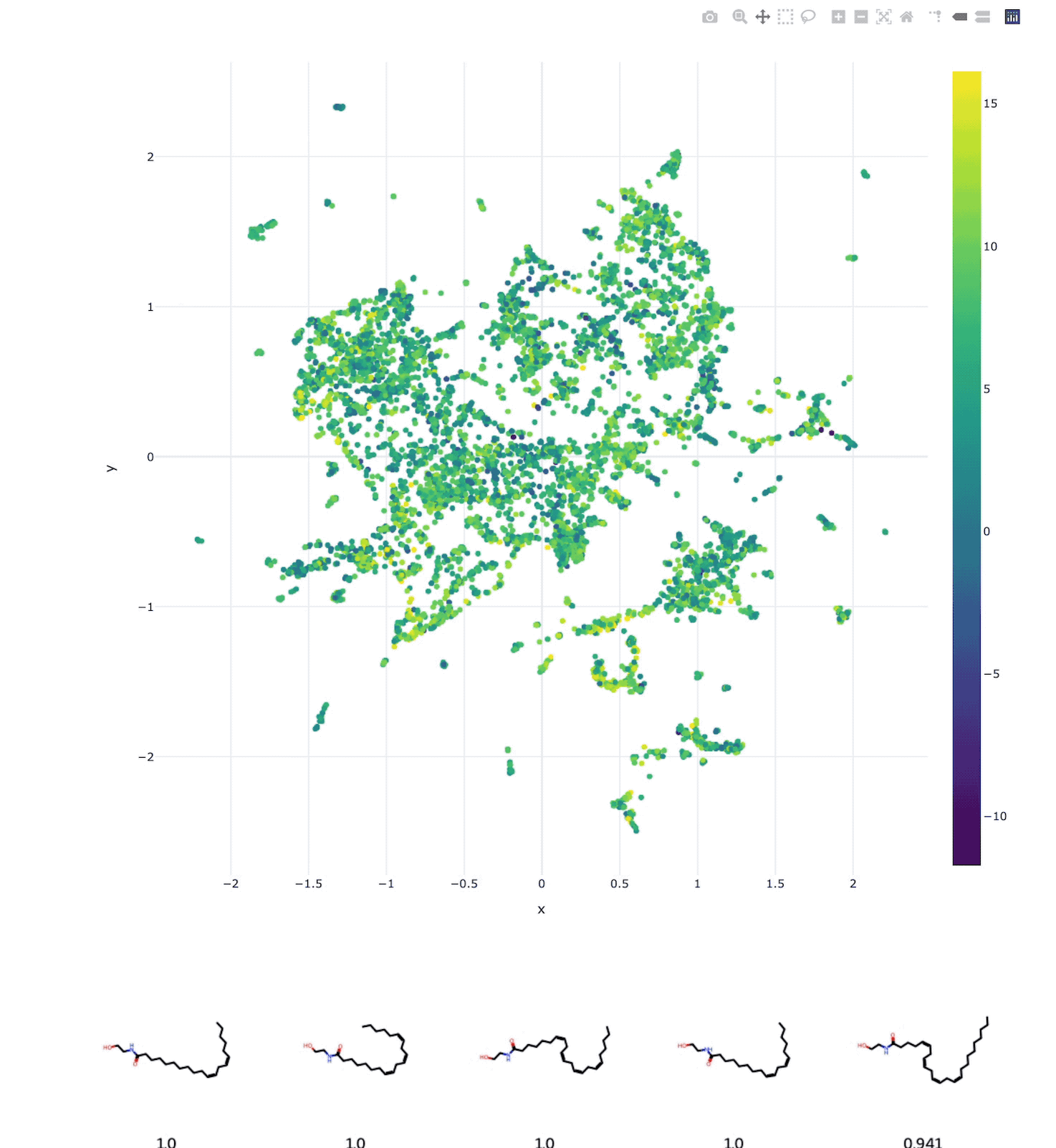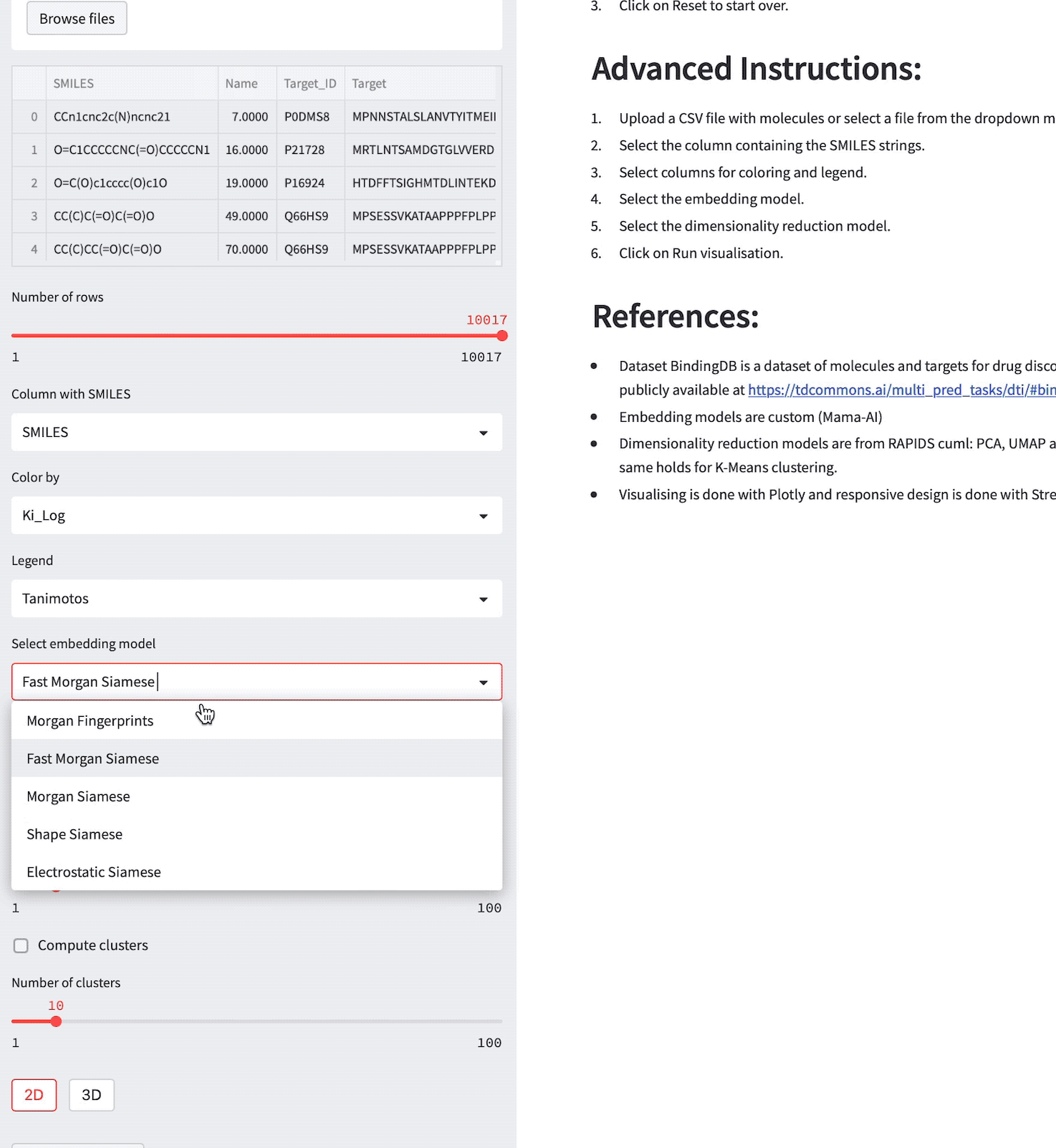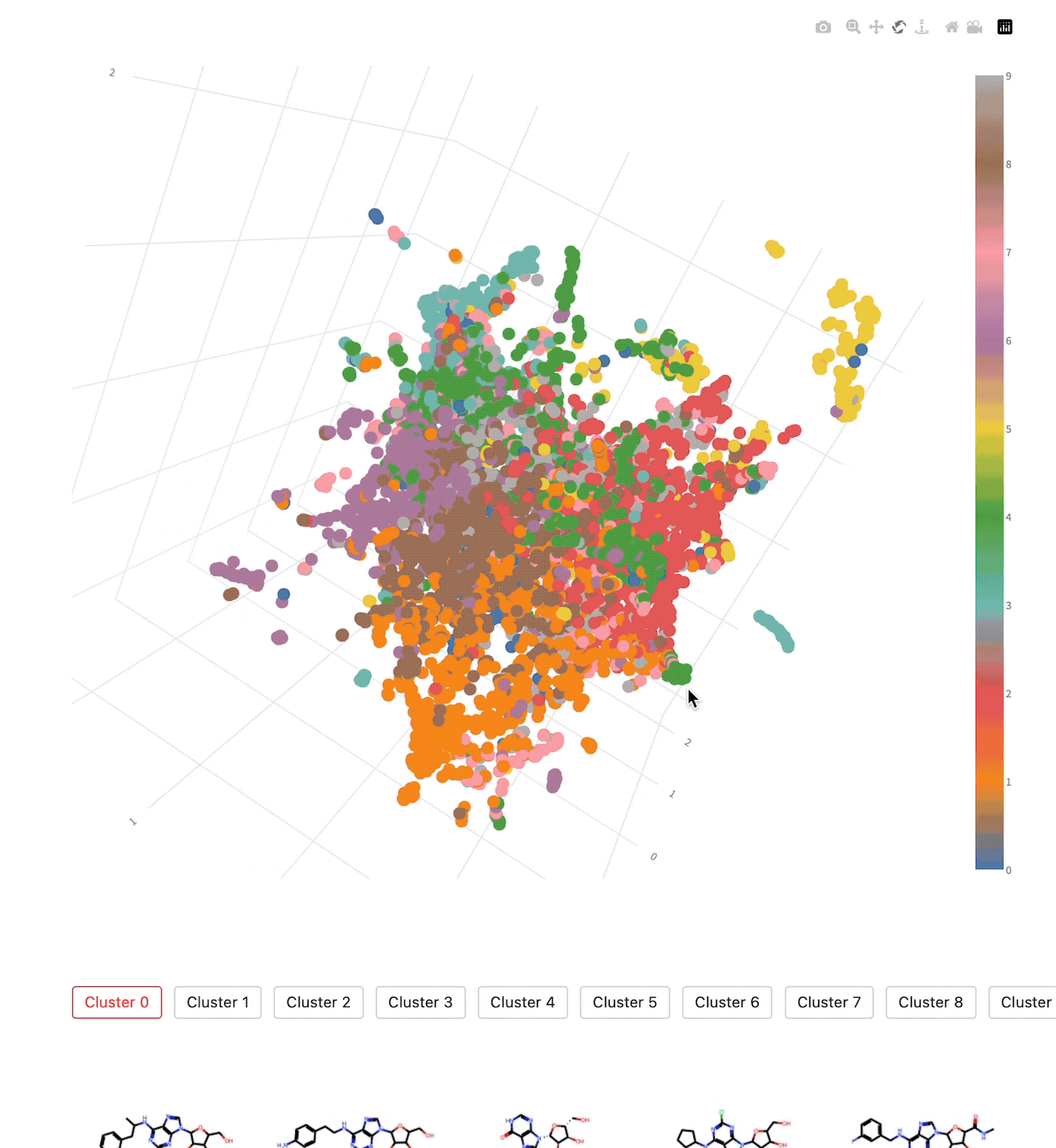
Molecular Latent Space Explorer
Our AI-based Molecular Search tool CHEESE is able to generate chemical representations based on shape and electrostatic similarity and it is very fast at doing that. These representations can be plotted via dimensionality reduction and you can visualise the dataset, color it by clusters or by some property and explore data points (molecules) close to each other. In the video we are working with a dataset of 10000 molecules based on BindingDB. In the latent space it holds that the datapoints are interpretable, because distances between them correlate highly with their real similarities. While other AI models cannot usually make any guarantees on the interpretability of their latent space, CHEESE is able to do so and it is possible to say that molecules which are 0.9 cosine similar or which have 0.1 euclidean distance do have proportionally the same fingerprint, shape or electrostatic similarity depending on the model. Subsequent clustering or similarity-network computation is possible as well.
Batch Search by Dataset
In this use case, we show that in vector space, it is possible to find a centroid of selected vectors or sample from their convex hull. This is what CHEESE centroid search or enrichment search does. By retrieving similar molecules to the centroid of our dataset, we will get the same „molecular topic“ or pharmacophore as of the molecules in the dataset. By sampling from the convex hull, we can enrich the dataset by more molecules fitting the probability distribution.
Advanced Search Queries
Is it possible to search based on similarity of one kind and dissimilarity of another kind? Or combine multiple similarities? Let’s say that scaffold hops are shape and electrostatically similar molecules that have low fingerprint similarity. And what about searching for molecules similar to a dataset of active compounds and dissimilar to a dataset of inactive compounds? In this prototype, advanced search options like this are possible. You can search based on two conditions of similarity or dissimilarity and even use the batch-search function described in our other prototype.
Human Interactome Protein Search
Is it possible to search protein sequences, similarly as we are searching for similar smiles? And what about the sequences of interacting proteins? Using CHEESE architecture, we trained a model on a dataset of Human Interactome (HURI) and achieved reasonable accuracy (cca 80%) in predicting protein-protein interactions. In this prototype, it is possible to search by a novel protein sequence and retrieve human proteins that are probable to interact with the query protein.2
Virtual Screening Pipelines
We perceive an opportunity to incorporate the CHEESE search as a sampling method within a virtual screening pipeline. This methodology would closely evaluate only a small subset of a large database, and iteratively enhance the structure-property relationship model, thereby optimizing the search targeting. Unlike brute-force processing of the entire database, this approach allows us to process just a relevant fraction of molecules via resource-intensive docking computations, and update models based on the outcomes after each iteration. This method, known as active learning, is elaborated upon in the MolIpal paper, as depicted in the figure below.3
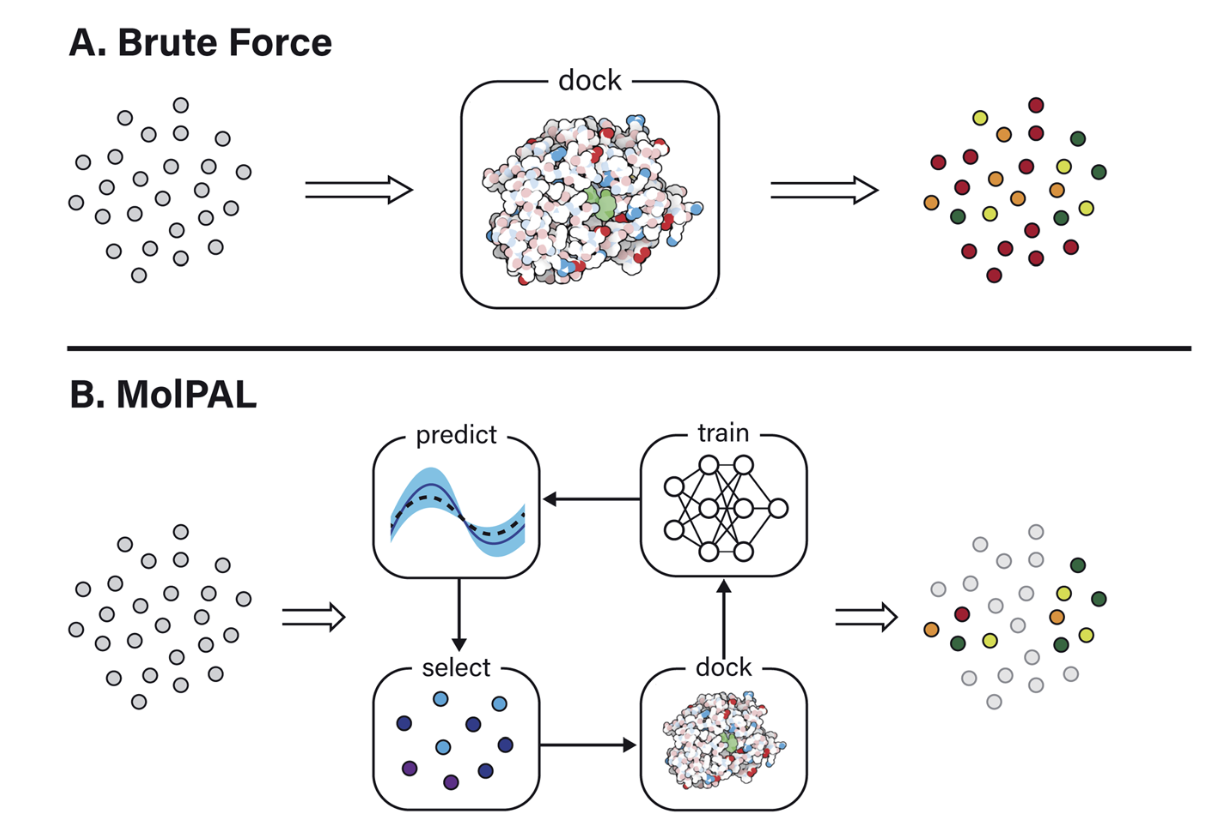
-
Prototypes are meant as a proof of concept or a feature preview and we don't provide any validity guarantees for the results. ↩
-
For the dataset see Luck, K., Kim, DK., Lambourne, L. et al. A reference map of the human binary protein interactome. Nature 580, 402–408 (2020). https://doi.org/10.1038/s41586-020-21… ↩
-
Accelerating high-throughput virtual screening through molecular pool-based active learning. Graff, D. E., Shakhnovich, E. I. & Coley, C. W. Chem. Sci. 12, 7866–7881 (2021). DOI: 10.1039/d0sc06805e ↩